Content¶
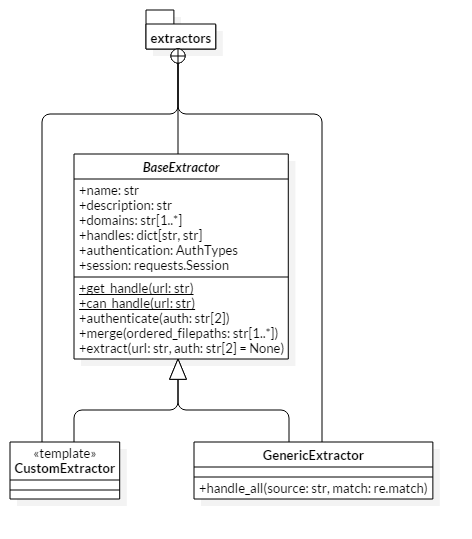
The Content is a simple object which stores all the required information needed to download something.
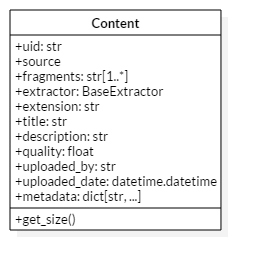
Most of the attributes in this object is sugar used for better representing the content.
The only three that really matter are the uid, extractor, and fragments.
The uid is simply a unique identifier for the content.
The extractor is just a reference to the BaseExtractor subclass that was used to extract the content.
The actual urls which need to be downloaded to form the full content are items in the fragments list.
In most cases the length of this list is 1 (because the raw content is not hosted as segments).
However, for sites that do stream segments of media, it most likely means that the length of the fragments list will be more than one.
Because of these fragments, it is necessary to calculate the size of the full content.
This is performed through the get_size() method.